RESIDE-IC Web Applications
Introduction
This page describes some aspects to think about when considering a new RESIDE web application to present research:
- why a research team might want a web application
- whether a Shiny app or full web application would better meet their needs
- the components of a full research web application
- what we require from research in order to build an interface to it which a new web application can use
- some different patterns of application we can provide
Why have a web application?
..as opposed to making research code available for users to download and run themselves?
Web apps are:
- Accessible: no special skills or coding knowledge are required from the user
- Available: on all devices with a network connection, and have no special requirements of the user’s local computer other than a modern browser.
- Secure: password-based access can be provided so only authorised users have access to sensitive data and functionality
- Fast: can be deployed to appropriate compute resources so intensive tasks can be executed as quickly as possible.
- Reliable: can deploy known stable versions of research code - this helps with reproducible research
- Easy to use: we can design the user experience to focus on their concerns e.g. particular practical or policy goals, or a need to explore a research model in a guided way with appropriate visualisations.
- Convenient: can allow users to easily save, manage and share their data and sessions. Users do not need direct access to large datasets required for code execution
- A useful starting point for advanced users: a web app allows other researchers to quickly assess the utility of a model before putting in effort to download, configure and run it locally.
What about Shiny?
Shiny is a popular choice for researchers wishing to provide web access to their models developed in R, but it has some drawbacks.
Pros:
- rapid web application development within R: easy to integrate with existing R-based research code
- easy to get started
- powerful presentation features
Cons:
- difficult/impossible to automate tests in order to be confident that new features have not broken existing functionality
- slow
- does not scale easily
- limited capabilities for many application features e.g. user authentication, or managing saved user data
- handles long-running processes poorly, causing the application to hang
In our experience, Shiny can be a good choice for relatively simple applications with no complex interactivity or scalability requirements. Within DIDE, we can deploy Shiny apps to our Shiny server, which can help by providing load balancing . Shiny also works well where the application is written over a single period and then not modified going forward. Where an application will need to evolve over time as new features are added, the quick startup time of Shiny is replaced by a slow and error-prone development process
In cases where Shiny’s limitations mean that it would not be the best choice for a final application to present to users, it can still be a useful prototyping tool, allowing the research team to develop ideas for how an application’s user interface should be structured and what options it should provide. The RESIDE team could then migrate the prototype Shiny app’s functionality to a full web application.
Components of a full research web application
Our web application installations typically consist of three main components:
- research code - provided by the research team
- an interface layer - this provides a way for the web application to provide inputs and receive outputs from the research code. It is usually written in the same language as the research code and invokes it directly, or via a task queue. The interface layer usually provides a local HTTP API which is accessible to the web application
- web application, consisting of two parts:
- back end: e.g kotlin or express.js, which forwards requests to the interface layer, and can do various bits of housekeeping, like managing persistent user data or uploaded files.
- front end: e.g Vue.js or React which is loaded in the user’s browser and provides the user interface and visualisations.
We run all of these components within docker containers to provide reliable portability between installation environments. Typically the front and back ends of the web applications will go into one container, and the research code and interface layer will go into another. We’ll run a web proxy in a third container, and there may be additional containers for databases, task queues etc.
Pre-requisites
In order to support this architecture, we require the research code to have the following features so that we can build a stable interface to it:
-
Source-controlled in git: we maintain the source code for our applications in git repositories, and we require research code to be available in git too, so that we can develop against it, and deploy it using docker.
-
Versioned: it’s useful to be able to surface a version number in the application, of both the research and application code, so that we can always be sure what version is deployed. It’s helpful if the research code can provide its own semantic version, but as a minimum we could use a git commit identifier.
-
Data sets are available and clearly defined: any data required for the application (data which is used by the research code, or has been generated by it) should be available to automated access for testing and deployment. This could be on a network drive, but it would be preferable if it was in something like a github release. Data should also be versioned in some way, and its format should be identical between versions, except for known format upgrades.
-
Stable: we need to be able to rely on the research code to have a known interface and to run reliably. It’s ok for the interface to evolve, as long as we can prepare for that in advance by updating the interface layer, and merging those changes into the research code and interface layer at the same time (along with any changes which might be required in the web application too). That way we can have a working main branch in all repositories all the time. It may be appropriate for some interface changes to be managed as evolving metadata so that application code does not need to change e.g. when a parameter is added.
-
Tested: it’s good if the research code can have at least a basic suite of tests which can be run to confirm functionality - it’s often difficult to test exact output values from research code (e.g. if it is stochastic), but it’s useful to at least test that results are being successfully returned in the expected format.
-
Long-running processes can be identified: if research code invoked by the user from the application is going to take more than a couple of seconds to run, then it will need to complete after the initial web request returns. We’ll need to know which processes this applies to, so we can design status polling and user notification accordingly.
-
Can be run within a Continuous Integration workflow: we can be confident that the code remains functional by creating a continuous integration workflow, an automated process of building and testing whenever changes are made. Source control and an automated test suite are required for this.
In addition, the research team will need to provide us with a good idea of the purpose, users and requirements of the application. It’s ok for there to be multiple user groups, but we need to have a clear idea of who they are and how we will separate functionality for them. If there is a Shiny prototype we may use that as a starting point - if not, we will probably start by creating some mockups to agree on the general flow and functionality of the app.
Application Patterns
Almost all of our applications involve the user providing some input (data files, parameter values), triggering some analysis and then observing or downloading results. Different research and different user motivations call for slightly different user experiences in the app. Here are some examples of different styles of applications we have written:
Long-running model
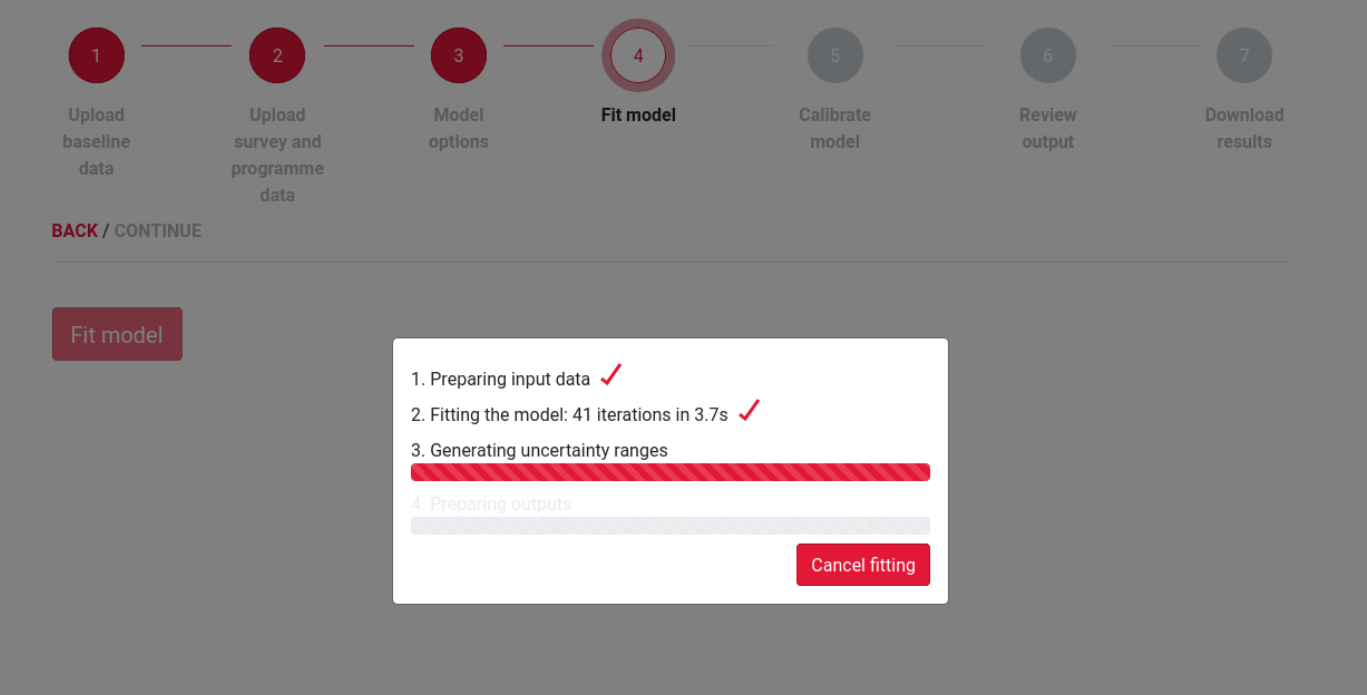
HINT runs the Naomi model for HIV indicators. The user uploads survey and other data, or imports it automatically from the AIDS Data Repository, and sets model parameters. The user then runs the model code, which can take several minutes. The web app polls the interface layer and provides status updates while the model is running. The user can then explore the output data in the web app, and can download output and summary data too.
Pre-run model for intervention strategy
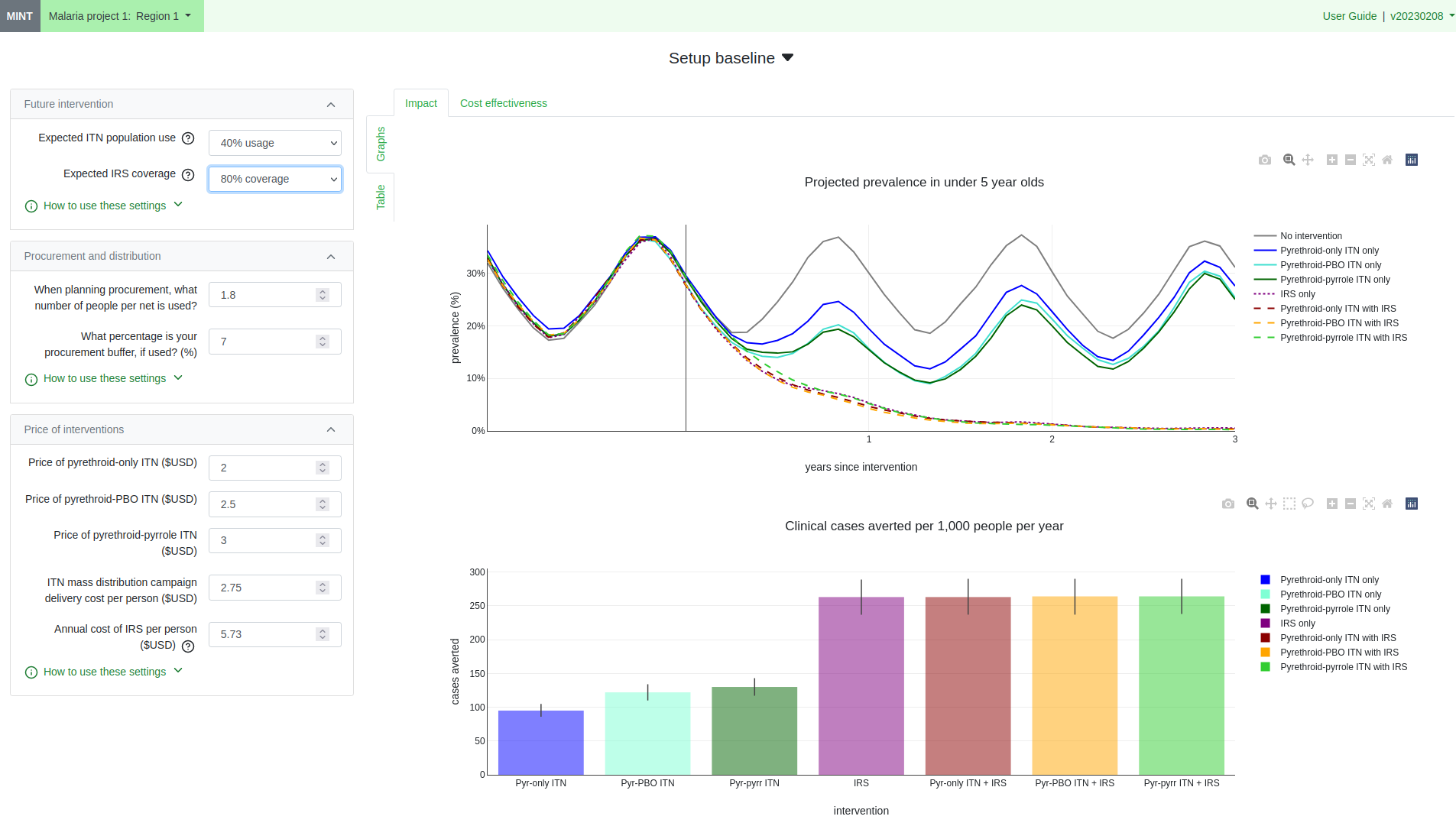
MINT provides the user with access to a pre-run dataset of expected malaria prevalence and cases averted given various intervention options and regional characteristics. The app is tailored to guide decision making on best allocation of a budget. Because the data is pre-calculated, there are no long-running processes to manage.
A disadvantage of this pre-canned approach is that it only provides results for a limited set of parameter values. The next stage will be to run a lightweight surrogate model on-demand. This will be trained on the original model, and will be capable of interpolating between the parameter values used to produce the pre-run result set, so we should be able to give users more relevant outputs for their regions.
Model exploration
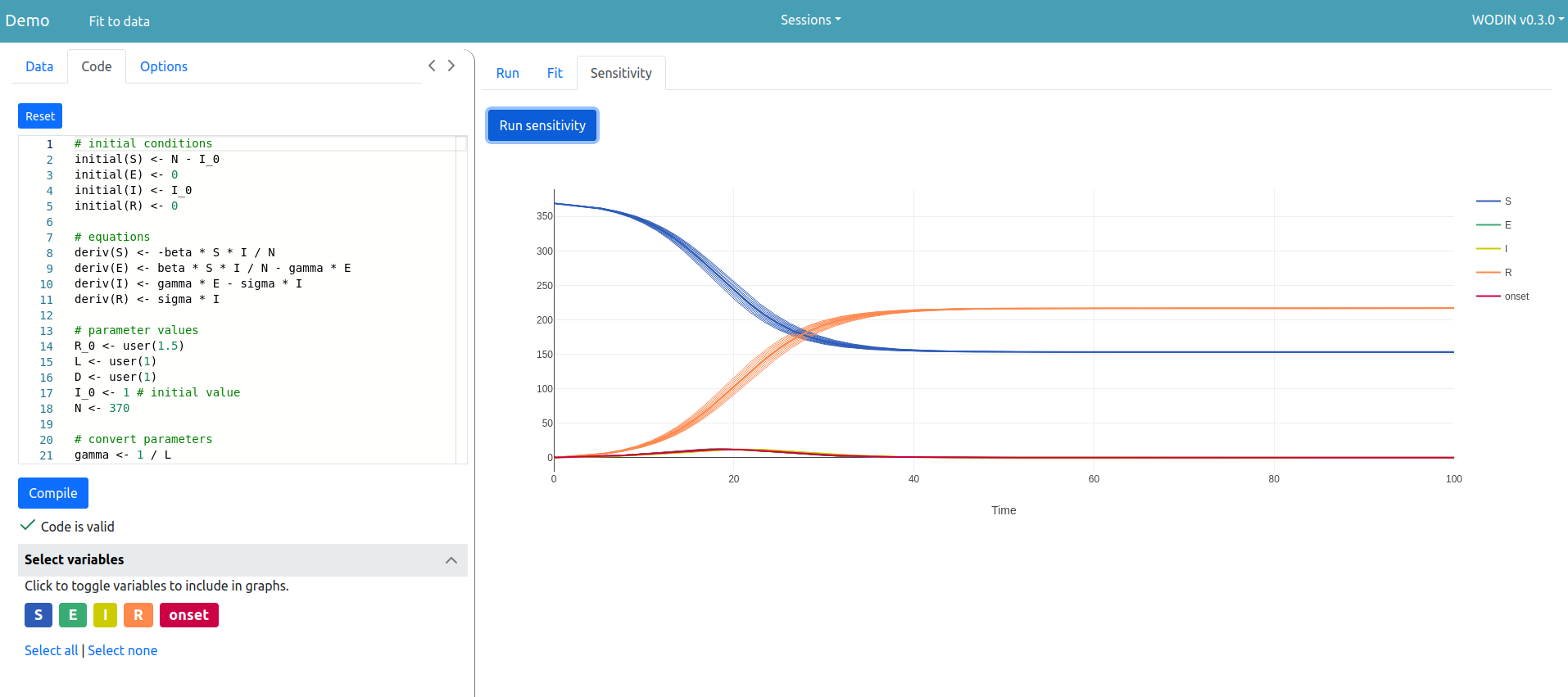
WODIN allows the user to create, edit and explore a model written in ODIN. While this is primarily being used as a teaching tool, it could also be used to present a model (it can include default model code) and allow the user to run it, fit it to data, try their own code tweaks etc.
Applying multiple analyses
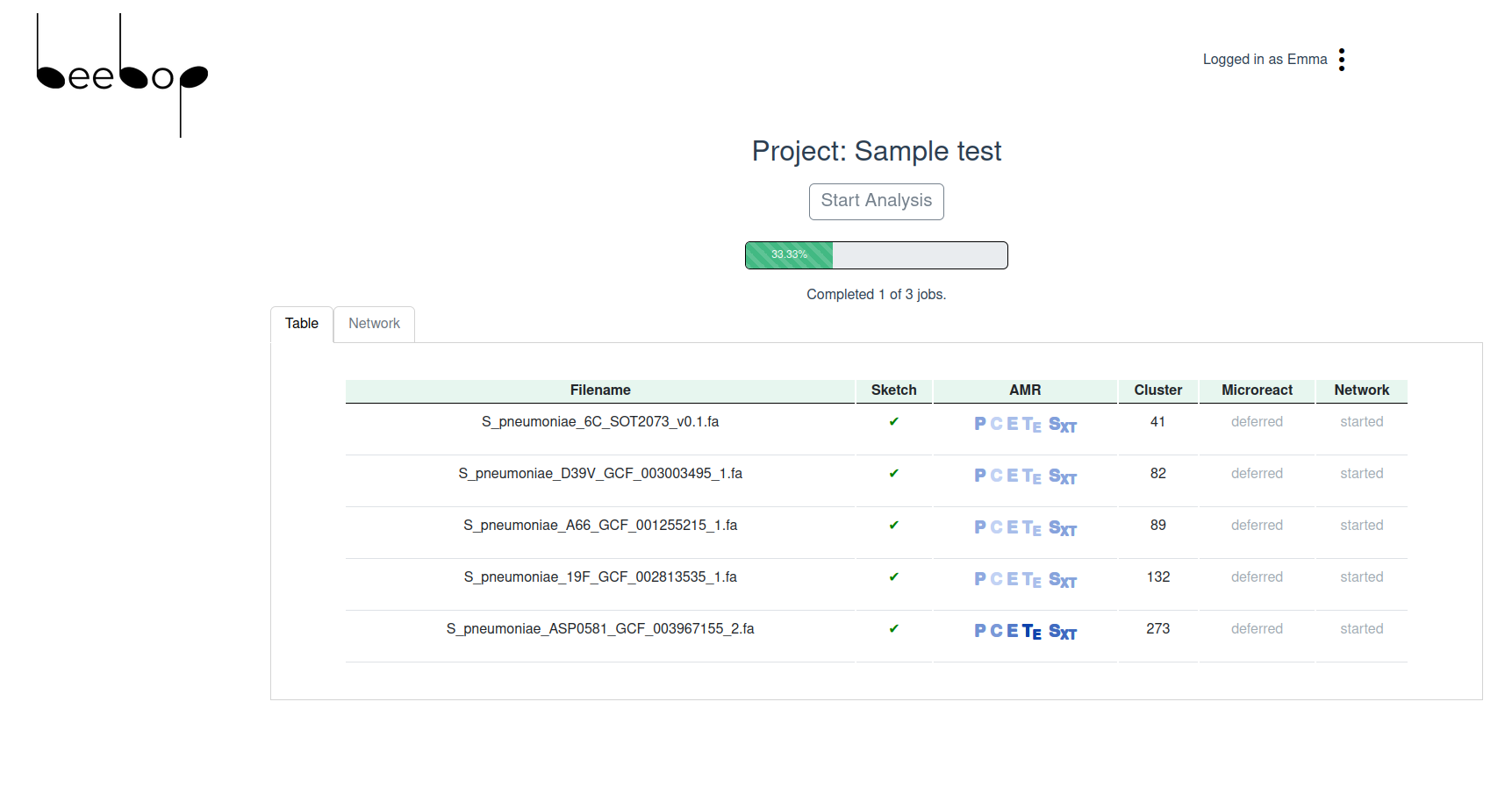
Beebop allows the user to upload fasta sample files and view results from a suite of analyses, some of which are performed in the browser, and others in back end research code in a long-running process. The full sample file is summarised into a sketch file which is sent to the research code, minimising network traffic and allowing sensitive raw data to remain private to the user’s computer. The Beebop application displays all results to the user as they become available.
Further reading
The Research Web Application Cookbook - presentation from 2021
